Låt oss diskutera sökning på internet - kanske närmare perspektiv sökmotor resp. entiteter betraktande generell tillståndsinformation synlig - utan särskilt mål annat än att uttrycka vad en SERP är för läsaren av sökresultatet.
Koncept. Vad vi skriver i sökrutan.
Mer fokus på hur det ser relaterat tillståndsinformation det motsvarar även när tillståndsinformationen är reducerad sammmanfattad över annat.
- 1. Vikter och skattningar: NGRAM- och språkmodeller
- 1.1. Antal resultat för koncept
- 1.2. Antal sökningar på koncept
- 1.3. Antalet läsare av allt i resp. sökresultat
- 1.4. Antal dollar / kr för koncept
- 1.5. Abstrakta värden (kronor vi ej enkelt kan handla för)
- 2. "Rubrikerna" i SERP
- 2.1. Rekursion och arbetsminne
- 2.2. Snippet
- 3. Rekommenderade sökningar
- 4. Volym sökningar igen: Bing - Google
1. Vikter och skattningar: NGRAM- och språkmodeller
Vi konstaterar först att vi har tre grundläggande variabler för två mycket ofta använda både i information direkt läsbar för den söker eller den som påverkar vad synligt via kanaler för reklam.
1.1. Antal resultat för koncept
För index över koncept i ett tidsfönster ej äldre än T[1] och ej yngre än T[2]: Hur troligt / vanligt relativt alla index över samma tidsfönster är att något relevant publicerats.
1.1.1.a För ett tidsfönster gäller att resultat publicerade inom det kan argumenteras ha ett minsta antal läsare approximativt samma som antalet artiklar i tidsfönster. Därför att skribenten har läst resp. innehåll själv.
1.1.1.b Ett problemområde blir tydligt när tidsfönstret expanderar genom att ökat fönster tenderar (tycks det för mig) göra det mindre trivialt att filtrera ut innehåll publicerat av datasystem för innehåll och presentation (jämför alla sidor i en webbutik dynamiskt formade utifrån olika perspektiv som en spindel ibland kan ta ut fler i antal än webbutik troligt haft totalt antal människo-sidvisningar).
1.1.1.c Normalt tidsfönster för sökmotorer som Google och Bing för webben allmänt är många år. Antal indikerade skattas troligen ofta från motsvarande en språkmodell ev. härrörande från hur data är organiserat (en försvarlig andel sökningar görs troligt över en ganska lång tidsperiod inte av mer än en eller ett fåtal: möjligt är det exakta antalet träffar vad som fodrar att någon vandrar bakåt görande resultaten behövda vilka kanske inte ens innan "fuzzy" därifrån framåt kanske finns beräknade i index).
1.2. Antal sökningar på koncept
För index över koncept i ett tidsfönster ej äldre än T[1] och ej yngre än T[2]: Hur troligt / vanligt relativt alla index över samma tidsfönster är att någon söker på koncept.
1.2.1 Emedan antal resultat ofta publiceras med en indikation tillsammans med SERP anges detta typiskt inte och är inte helt trivialt att få vettiga skattningar av också när ganska grova antal söks (eller snarast dessa medan det kanske rent av är enklare att få söka förändringar givet en utgångspunkt).
1.2.2. För primitiver / grundteorier för hur sökresultat kan beräknas gäller för huvuddelen i domän av query model ( P(Q) ) att man snarast undviker att använda faktiska värden för sannolikheten avseende respektive sökning. Vi kan ju annars tänka oss att när sannolikheten för ett resultat i SERP ska beräknas betraktat som ett där antal koncept lokaliserade givet koncept Q att trafik för del-koncept i koncept resp. lokaliserade koncept kan användas som vikt.
1.2.3. Skattande värden för query volum via flera i sig begränsade källor - och delvis ej direkt från sökmotorer - är det ganska tydligt att just för användningen typisk i 1.2.2. är kanske datakvaliteten för de flesta inte sådan att man vinner särskilt på att använda skattningar av query volym (andra former av vikter och modeller kan tillföra tydligt värde).
1.3. Antalet läsare av allt i resp. sökresultat
Från 1.1. och 1.2:
För tidsfönster p.s.s. som tidigare kan vi för allt indexerat förenklat skatta totalta antalet läsare som summan av de som söker och de som skriver.
1.3.1. Ovan under förutsättning att trafik som når resp. i övrigt är försumbart alt. att summan i övrigt implict kan ge en skattning av trafiken i övrigt.
1.3.2. För stora entiteter med många läsare för innehåll i index är det mycket tänktbart att när de länkar (ex. för en del innehåll hos några av internets tio största tidningar på engelska förekommer ibland länkar till varandra för referens) att det ger märkbar påverkan.
1.3.3. Över en webb med en mängd läsare uttryckande en respons via bloggar, sociala media m.m. är det tänkbart att det också ger påverkan via trafik av andra. Trafiken resp. skribent skapande sådan respons (säg när vi kan klara att se dem entydiga d.v.s. en människa gör respons på en plats) är jag ganska trygg skattas vettigt från query volum om man har den och tror jag men vet ej säkert hur väl och var större avvikelser kommer från mängden innehåll publicerat större entiteter stationära uttryck läsare är kända för.
1.3.4. Mängden länkar enligt 1.3.2 och 1.3.3. tycks bedömt från data jag läser in vara tämligen begränsat i mängd träffande ett sannolikt index relativt det antal som kan argumenteras representeras av endast skribenterna av respons i sig. D.v.s. utgår vi från att ingen läser deras respons mer än dom själva och att de faktiskt besökt och läst vad de länkar är det ändå en ganska begränsad mängd trafik givet mängden respons-data jag samplat (säg från några testperioder totalt cirka 100 GB rss- och atom-strömmar med en försvarlig andel av kända bloggtjänster där default är att hela strömmen publicerat). D.v.s. "ganska" mycket data krävs här resp. alt. att en vettigt korrekt trafikskattning av vilka respons-entiteter som kanske avviker uppåt för vilken trafik de ger.
1.3.5. Jag tror eller lutar åt att för de flesta som söker skattningar av respons att det enklare och kanske ofta korrektare är att söka sampla väldigt många entiteter troligt beskrivna en individ vardera och betrakta dem tillsammans snarare än att när tidsfönster är tämligen smalt (säg från någon timme upp till ett par veckor för nyheter) ge hög andel eller alls beakta rekursiva trafik-skattningar för resp. respons-entitet. D.v.s. en riktigt hög andel Twitter, Google Plus, Wordpress.com-blogg,Blogger-blogg,Tumblr.com-blog-community-grunka o.s.v. är enklar att komma rätt med i "laplace-smoothing" viktning om vi kan ta väldigt många entiteter.
1.4. Antal dollar / kr för koncept
Vad jag egentligen menar här avstår jag bättre från att försöka ge en entydig definition av eftersom jag ännu inte byggt viktsystem klart för det. Vi kan emellertid konstatera vad känt både före och efter "internet".
1.4.1. Vi antar en "modell-sökmotor" som endast visar produkter och har full vetskap om antalet som söker. Priset för resp. produkt har ej ett självklart linjärt förhållandet till antalet som söker. Söker en miljon personer på car är kanske inte produkten överst som är bäst en bil utan kanske en bok eller annan informationsresurs om det. Tydligare indikation koncept om att vi är intresserade att köpa - "buy car" + "volvo 240" + "cheap" + "police auction" + "used in diamond_OR_gold hit and run" - bilen tänker jag har färr som söker på det men kan tänkas göra dyrare produkt i form av en bil till försäljning mer sannolikt genererande värde.
1.4.2. Förhållanet pris, trafik och koncept håller ej heller över SERP utan varierar med position och kan vara mer eller mindre varierade beroende på sökord.
1.4.3. För läsaren av sökresultat framgår priset för resp. resultat men ej hur mycket de genererar i intäkt. Värde manifest resp. latent existerar.
1.4.4. Priset är manifest och är vad vi löst kan jämföra med mer allmänna begrepp som status. Informationen - eller enklare variansen - är dock praktiskt styrande för alla sådana jämförelser över en SERP. Detta genom att ett högre latent värde för manifesta värden associerade status när konverterande till valuta gäller för typiskt tio resultat per sida att enstaka sådana stoppas in brett över koncept där mycket entydig statistik är vek för eller där det redan visat löna sig. Är variansen för ett manifest värde indikerande tänkbar status emellertid låg medan vi skattar query volumen hög är det dock kanske troligare dollar-status associerat.
1.4.5. P.s.s. enligt 1.4.4. existerar låg-pris paketeringar där ev. status är mindre associerad till att realisera värdet av det. Ex. en bok, sekundär informationsresurs i form av hemsida o.s.v.
För index över koncept i ett tidsfönster ej äldre än T[1] och ej yngre än T[2]: Hur troligt / vanligt relativt alla index över samma tidsfönster är att någon söker på koncept.
1.5. Abstrakta värden (kronor vi ej enkelt kan handla för)
1.5.1. Försök att uttrycka sådana värden - ofta näraliggande uttryck av den större flock personer på nätet - börjar bli ganska vanligt. Längre tillbaka var ett fåtal annat än ovanliga (bl.a. Google PR och Alexa ranking). Numera försöker sökmotorer oftare addera information om sådant som recensioner, tweets och jämförbart.
1.5.2. Att uttrycka både dessa "reaktioner" och "vad" som uttryckt dem är tämligen svårt redan i visuellt utrymme. Och ännu svårare (tror jag) i tolkning av vilka som gjort dem och vad de är i meningsfull "flock-mening" för den som söker.
1.5.3. Status och andra värden associerat flock behöver ju komma med en förståelse av vad den underliggande valutan är. Är det en valuta person som söker informationen är intresserad av alls? Och på vilken nivå växlar den in för denne. En del personer värderar information mer från en viss flock och mindre eller rent av negativt från en annan.
1.5.4. Är sådan association vad som svårligen framgår eller kanske inte ens går att enkelt se faller uttrycken ner till enklare standard-uttryck utan "brand power" från flock. Kostnaden för att betrakta det föreligger fortfarande och behöver utan extra hjälp av "brand power" drivas av en historik av värde av att utnyttjat det troligare närmare konkret och rationellt bedömt än mer abstrakta värden, upplevda känslor eller default donerat värde oavsett resultat av att stämma närmare en flock vi gillar.
1.5.5. Att skapa uttryck av dessa reaktioner utan att addera en problematisk nivå av kostnad innan ev. värde levereras användare kan därför vara väldigt svårt.
1.5.6. Bättre mer framarbetade uttryck utifrån en mängd responer är självklart möjligt men kräver värdering av de underliggande responserna. Av upplever jag ordentligt att döma av vad jag ser praktiskt sökande själv ligger en stor utmaning för sökmotorerna här. Tänkbart är det primära värdet för dem just nu av att visa dom enlare reaktionerna att lära sig att värdera dem (ex. filtrerande ut sådant som recensioner egentligen gjorda eller beställda av den som säljer en associerad produkt).
1.5.7. Utmaningen i sådan värdering kan jämföras med möjligheten att värdera en länk som en besökare för varje entitet vi tror är en individ. Men skillnaden att vi antagligen har ordentligt färre responser från denna grupp att värdera jämfört med hur många som är en "elegantare" / "smutsigare" (från mitt perspektiv tar jag verkligen ingen ställning: både riktiga och köpta recensioner är bra data att analysera byggande information om värden associerade koncept från olika perspektiv och jag har föga problem att särskilja dem - och i enstaka manuella kontroller byggt från etablering erfarenhet längre bak kan jag ganska ofta rent av se vilken entitet som gör marknadsföringen och ibland troligare skrivit det).
2. "Rubrikerna" i SERP
Vi har information i SERP uttryckt för resp. resultat. Denna kan vara mer av vad jag bredare kallar DO och vi enklare här ser som "rubriker" eller i "fetstil". Vidare vad jag kallar DESCRIBE - givet ett DO vad som sätter kontext för koncept i DO och vars tolkning och förståelse styrs och påverkas från primacy effect av aktuellt DO - och typiskt för sökresultat snippets.
2.1. Rekursion och arbetsminne
2.1.1.1. Vi vi enkelt och effektivt skummande tar in i arbetsminne är en funktion av uppmärksamhet / motivation / exakthet vi är beredda att investera för visuell yta och dess visuella komplexitet. Desto mindre uppmärksamhet / motivation / exakthet ju hårdare skummare vi efter tydliga träffar med hög "vikt / potens" (ex. i vissa sammanhang brand power tillsammans med starkt emotionellt uttryck likt fiktiva rubrik och första rad snippet: Google VP stabbed Microsoft CEO with sword in new release of computer game).
2.1.1.2. Resp. där behandlat läggs i kontextuellt pågående motsvarande direkt vad vi ser i en vanlig scen i vardagen. Av betydelse, understrykt och av typ vi specifikt söker läggs i arbetsminne.
2.1.1.3. Vi kan göra switch av kontext pågående i arbetsminne. Är det kontextuella avståndet kortare kommer det med lägre kostnad och vad vi sökande information av allt att döma från mycket nvända kommersiella produkter är beredda att göra. Några exempel:
- Andra resultat - ex. nyheter - i webbsökning.
- Presenterande resultat i SERP av en viss typ. Jämför hur Google bl.a. söker föra in resultat av typ nyheter eller sociala media i webbsökning.
- Jag spekulerar att det tänkbart är dyrare switch än övriga men värdet är ju också en funktion av antalet som faktiskt söker just information av denna sort resp. typ resp. hur väl de klarar att hitta samma innehåll allmänt i webbsökning annars och/eller kommer rätt via användning ex. Google News.
- Dyrare därför att vår organisation av långsiktig vetskap om hur här relevant koncept förhåller sig varandra - tänkbart underliggande och åtminstone påverkande hur arbetsminne är funktionellt - är topologiskt organiserat via närhet av dem. D.v.s. den närmare topologiska motsvarigheten i spatiell mening är ex. förhållandet "nyhet" eller "webbresultat" d.v.s. ungefär det samma över ett ganska få typer. Medan distansen koncepten kommer tendera att vara större mot det större flertalets intresse (troligare irrelevant i perspektiv av en genomsnittlig sökare).
- Störning för större flertalet totalt givet relativt få insprängda resultat enkla att "aldrig se" eller betrakta är tänkbart lågt jämfört med värde för dem som faktiskt söker något av typen enligt två eller är allmänt prospekterande. Kostnaden switch är med andra ord vad vi kan lära oss att undvika.
- Enklare att resonera om är rekursiva uttryck av mer exakt information.
- Givet ett resultat bland tio på en sida - låt oss jämföra det med en rubrik på nivå 1 - kan vi för det ge mer information. Konstruktionen används bl.a. av Amazon.
- Besläktat ofta utnyttjad är att länka föreslagna andra sökresultat vilket vi dock inte avser här.
- Istället avser vi när denna mer exakta information ges på samma sida i form av visuellt associerad information motsvarande en rubrik nivå större än ett (helt normalt underliggande ev. med mindre font eller annan visuell paketering som gör att det stör mindre för den som ej var alls intresserad av nivå ett).
- Läsaren ser information på nivå ett för ett resultat. Det intresserar denne. Informationen på nivå två filtreras ej bort för detta resultat och switch till ett mer exakt kontext sker: informationen nivå två går in i arbetsminne.
- "Vi" (jag) kallar denna operation för rekursivt innåt. När besläktat i organisation information är upp - associerat men bredar i vad som avses - och ner - associerat smalare mer exkat - i thesaurus och för båda från ett troligt perspektiv av vad som avses avgränsat av koncept vi utgår från.
- Gör vi därefter rekursivt uttåt återkommer vi föregående nivå. Förkastades mer exakt som ej ledande till avslut påverkar de ej i introduktion av något nytt i det arbetsminne vi återkommer till. Även om det gäller när vi tänker oss biologiskt modell av arbetsminne påverkad av organisation koncept i långtidsminne - vilket menar jag är ytterst rimligt eftersom denna organisation uppenbart påverkar och styr hur vi resonerar och laborerar med vad aktiverat i arbetsminne - gäller att viss post-aktivitet kan inverka. En aktivering av något ointressant i ett uttryckt rekursivt innåt kan tänkas inverka när vi ser något annat efterföljande om än mindre troligt än något direkt tillsammans med sådant resultat.
2.1.2. Den visuella naturen av 2.1.1 ligger nära perfektion när det kan uttryckas organiserat jämförbart men när rekursivt ovanför ej störande visuellt. Ex. listor ungefär motsvarande ranking från 1 till 10 på nivån ovanför. Antalet behöver emellertid vara fler där historiken bakom tio resultat tänkbart blev möjligt och standard delvis därför att två visuella centraliteter togs ut efter varandra genom ett pagedown förr när upplösningen på datorer var annorlunda. Vidare ligger belastning redan givet från koppling till kontext rekursivt ovanför. Tänkbart (jag vet inte exakt var nivån ligger) cirka fem objekt.
2.2. Snippet
2.2.1. Sökresultat organiserar sig dock ej enligt 2.1.1 och 2.1.2 som vanligast där det normala istället är the snippet. Denna ger dels uttryck som är av DESCRIBE mot aktuellts resultatts DO (här titel) med koncept från sökningen styrande vilket DESCRIBE som plockas ut från sidan vanligen markerat med fetstil. Jag finner det lätt problematiskt att enkelt passa in det i mitt resonemangssystem av DO och DESCRIBE. Det är från tror jag troligare ren DESCRIBE (ex. brödtext i en artikel) men agerar här DO i den mån läsaren betraktar informationen och därefter går vidare och läser hela artikeln (d.v.s. kommer påverka vår förväntan om vad vi där kommer läsa) men ger ju också om vi ej gör det en DESCRIBE för direkt i SERP uttryckt DO:
2.2.1.1 När betraktar snippet som DESCRIBE av aktuellt DO i sökresultat läst men ej resulterande av att läsaren går vidare till sida (låt oss anta en person som sitter och läser några sidor SERP:ar) gäller att "vetskap", "tolkningsrymd" för DO kommer påverkas av resp. DESCRIBE. Personen bygger en viss förväntan / vetskap om vad en viss DO i ett sökresultat vanligen har för DESCRIBE i snippet.
2.2.1.2. Och över många sökresultat vilka koncept i DESCRIBE som oftare associerade till koncepten i resp. DO. Kanske rent av föranledande en särskild sökning. Eller inverkande på hur sannolikt personen väljer en rekommenderad besläktad sökning.
2.2.1.3. Dispergensen mellan snippet - från "transformation" DESCRIBE till DO - och rekommenderad besläktad sökning är dock ganska tydlig. Möjligen är ev. påverkan närmare en känsla av att "bottnat" ut vad ett sökresultat kan ge för att hamna rätt.
2.2.1.4. Det tycks för mig att åtminstone för Google är mer eller mindre det ändå syftet och värde av snippet att visa kontext sökorden förekommer utan mer "sofistikerade" metoder för association till besläktade manifesta eller latenta koncept troligare använda för att peka vidare till andra sökningar.
3. Rekommenderade sökningar
Sist betraktar vi dom rekommenderade sökningarna och vi kan där inkludera vad som direkt ges i rekommendationer i input-fältet. En försvarlig mängd standard-algoritmer ofta välkända innan i andra praktiska områden inom clustering av data av olika slag (inte minst just ord eller flergram eller entiteter av olika slag) finns. Mer praktiskt näraliggande den som söker kan vi dock konstatera att:
3.1. Dessa rekommendationer kan vara uttryck för rekursivt innåt. Givet koncept A kan vi föreslås koncept A + B där A + B kommer med ett antagande av att A ger en yttre avgränsning med ett antagande om en eller ett fåtal övergripande "ämnen" där B (som vi tänker oss kan erbjudas i ett fåtal vanligare alternativ) uttrycker en mer exakt aspekt av resp. sådant antagande.
För exemplet nedan från Google tycks ngram-modell användas där resp. adderat "sub-koncept" (ngram som kan adderas från listan) antagligen speglar sannolikhet från publicerat innehåll ev. med preferens mot en typ som antas bättre passande. Emellertid kan jag också tänka mig att sannolikhet från faktiska sökningar påverkar i den mån de finns. I sista exemplet där tips på payload söks - d.v.s. troligt väldigt osannolikt både över allt publicerat innehåll resp. vad folk söker på - faller förslagen ner till att föreslå resp. ord.
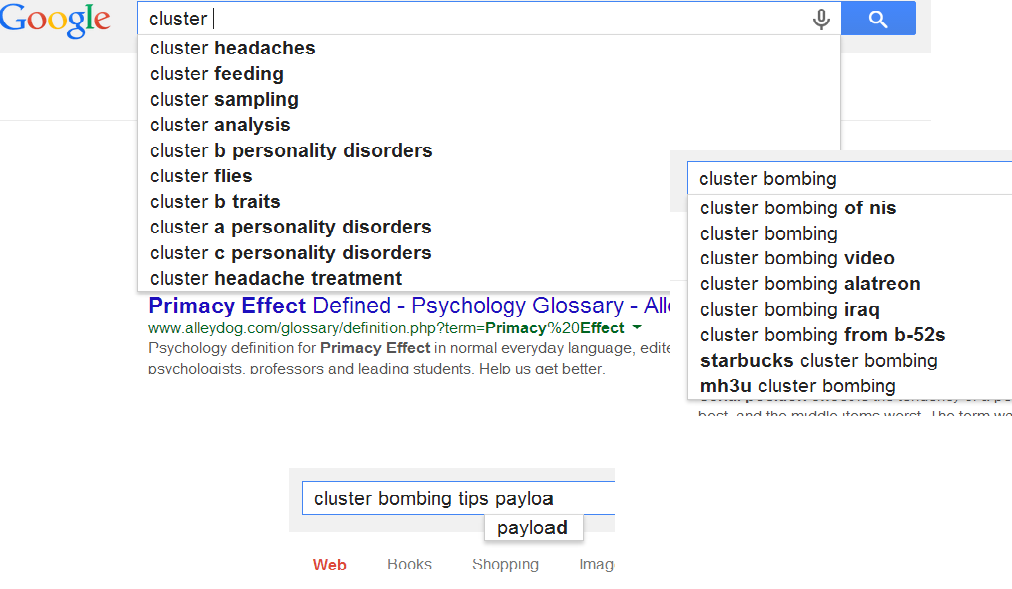
Thesaurus och liknande organisationer används också ofta. Näraliggande fortsatt med Google som exempel är definition av ett koncept motsvarande koncept sökt som bedöms troligare vara vad sökt eller vanligare uttryckt indikation om att man betraktar koncept möjliggörande sådan användning både här och i övrigt. Ett enkelt exempel är när vi i samma organisation också har entiteter (jämför ex. med Yago m.m. byggt från Wikipedia) och mer troligt hamnar rätt i förslag när en specifik artikel, bok eller film söks där man kanske inte minns hela titeln. Likt Library of Congress nedan:

Min erfarenhet från perspektiv sökande information pekar ganska tydligt på att storlek index och/eller mängd sökningar att analysera kan addera ordentligt värde oavsett om artiklar, böcker, film eller annat söks där man inte fullt minns vad det egentligen heter. Library of Congress koncept ovan till ganska stora delar byggda av ngram-modeller från titlarna är där praktiskt sämre för mig än Googels mycket blandade approach.
4. Volym sökningar igen: Bing - Google
Här har jag dessutom av och till nyligen funnit en spännande förändring i det relativa värde Bing leverar jämfört med Google. Längre bak presterande den för mig och många andra ganska dåligt. Sedan ett par år har Microsoft uppenbart bedömt bl.a. från artiklar publicerade såväl som presentationer (av och till riktigt ambitiösa såväl som användbara sammafattningar: ) gjort ett mycket ambitiöst arbete för att bygga långsiktigt grundvärde. Även om effekt av det nog var märkbart var det fram till nyligen inte på nivå att det egentligen motiverar mig att av och till försöka den.
Sedan kanske några månader nu märker jag emellertid att det kan prestera när jag inte på vettig tid får Google att visa vad jag vill hitta. Ett exempel är identifikation av sidan relateratMongoDB länkad i Sydsudan: Vapenvila efter inte avgörs av politisk förmåga och för resp. sida kraft att se dom egna problemen speglade hos "dom andra" (2014-05-12). Det var ej i URL den sida jag sökte men jag är övertygad om att det var exakt det innehåll jag sökte (vilket gör det mer intressant).
Orsaken torde ligga i att aktuellt stycke data hos Google är noterad på domän mycket kraftigare associerad MongoDB. Troligt den jag tyckte mig minnas att jag läst den på: antingen www.mongodb.org eller nära associerad. Men där som vanligt är - eller default bedömd från organisation plattformar publicering - uttryckt underliggande artiklarna ev. med pagination över kommentarer samtidigt som mängden sidor därifrån relaterat MongoDB är "enormt". Samma data publicerat andra sajter kan ändå konkurrera med det obefintliga resultatet från den MongoDB-tyngre sajten.
Den tänktbart mer styrande faktorn i vad som avgör skillnaden mellan Bing och Google när vi lämnar den MongoDB-tunga sajten med kamrater:
Kan tänkas komma ner till för Google-styrande verkan:
1. Eventuellt vikter relaterade till tidigare uttryckta långt bakåt i vår lista här:
"1.2.3. Skattande värden för query volum via flera i sig begränsade källor - och delvis ej direkt från sökmotorer - är det ganska tydligt att just för användningen typisk i 1.2.2. är kanske datakvaliteten för de flesta inte sådan att man vinner särskilt på att använda skattningar av query volym (andra former av vikter och modeller kan tillföra tydligt värde)."
Eller vad som motsvarar det. Likt hur jag såg att antingen Google eller Microsoft (minns jag rätt Google) patenterat något kring att beräkna similarity via de sökresultat man redan har i SERP:ar för att hjälpa surfaren till besläktade sökningar kan man så klart börja skatta länkar från egen trafik såväl som förr kanske mer trafik från länkar. Viss risk för "rundgång" - eller "stående vågor" - eller vad ska kalla det finns kanske ibland.
2. Och oavsett exakt vad som ger vikten tidigare diskuterat för Wikipedia-koncept i:
Där det som ett uttryckt av det kan vara oerhört svårt att söka information om Wikipedia, Wikimedia, Mediawiki m.m. Istället föreslås uppslagssidor i Wikipedia. Expansion av tillåtna egenskaper i vad relevant entitet publicerat ordentligt tilltagen där det mer exakta avgränsade område utanför det inte får plats.
Här är Vietnam vårt Wikipedia. Om vikten är trafik är det givetvis tilltalande attraktivt data att ha en av få riktigt feta samlingarna av men det är inte alltid trivialt att tänka sig mer exakt hur man bör låta det styra. Kanske (jag är inte riktigt säker på vad som egentligen sker: ids inte betrakta det överdrivet) föranleder större tyngd Vietnam i trafik en för min målsättning sökande irrationell expansion av vilka egenskaper relaterade Vietnam som tillåts visas där avgränsning från närmare relaterat MongoDB ej orkar inverka tillräckligt.


.jpg)



